Web Accessibility Evaluation Tools Only Produce a 60-70% Correctness
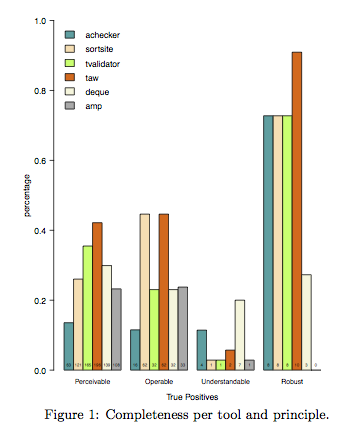 Completeness…
Completeness…
As you may already know, last week a critique appeared of a paper authored by three friends of mine, Markel Vigo, Justin Brown, and Vivian Conway. Indeed, Markel and I are colleagues in the same laboratory. This critique was written by Karl Groves regarding a paper entitled “Benchmarking web accessibility evaluation tools: measuring the harm of sole reliance on automated tests” and was published at the W4A2013 conference.
I read this paper at the time and I just re-read it over the weekend to re-familiarise myself with the contents. I’ve not read Karl’s critique before making comment on the paper as my intention is not to respond to the critique but restate what the paper says and why that’s important. Indeed, the title pretty much says it all, however, the abstract and the rest of the paper supports the statements expressed.
So what does the papers say?
- Web accessibility evaluation can be seen as a burden which can be alleviated by automated tools.
- In this case the use of automated web accessibility evaluation tools is becoming increasingly widespread.
- Many, who are not professional accessibility evaluators, are increasingly misunderstanding, or choosing to ignore, the advice of guidelines by missing out expert evaluation and/or user studies.
- This is because they mistakenly believe that web accessibility evaluation tools can automatically check conformance against all success criteria.
- This study shows that some of the most common tools might only achieve between 60 and 70% correctness in the results they return, and therefore makes the case that evaluation tools on their own are not enough.
The paper therefore hinges on the accuracy of evaluation tools, and so the experiments use four experts, one of which is a blind assistive technology user, to assess a set of pages as a ground truth. This ground truth serving as the baseline for comparison against the automated success criteria evaluation. A number of tools are compared, however in all cases they are found to under-perform.
The data for this study is open and available. In this case, as per the scientific method I am able to check empirically any assumptions made by the authors:
- If I do not like the webpages selected I may pick different ones,
- if I do not feel that the evaluators are truly experts, I may evaluate the webpages myself,
- if I do not agree with the choices of evaluation tool, then I could select a new set.
None of these changes would affect your ability to refute the contribution of this paper which is that web accessibility evaluation tools in and of themselves will only produce a 60 to 70% correctness. All other data as supplied with this paper (and often not supplied at all by authors preferring anecdotal evidence) is only there to remove the need for interested parties to re-collect data over all stages of the experiment.
- In the most expansive interpretation, the primary concern is the percentage correctness of the tools with regard to meeting success criteria when evaluating webpages. Indeed, we do not need to believe that the paper is generalisable because the method enables us to test it ourselves regardless of the pages selected, the evaluators performing the study, or the tools chosen.
- In the most limited interpretation, the percentage correctness of the tools selected, on the pages selected, on the date and time of evaluation was 60-70% when compared to the ratings of the evaluators - this constrained definition is all that the data is supplied, or required, to validate.
We might of course, in the future, evolve more intelligent tooling which may refute this work, THIS IS SCIENCE!
I suggest anyone wishing to disagree with this work perform the same experiments, once that data is collected then we may have a basis for discussion and critique, as opposed to anecdotal thought experiments.